FAT5: Flash Attention T5

While much effort has been devoted to optimising decoder transformers, thus abandoning the encoder, we believe it is essential to maintain an encoder-decoder architecture.
Indeed, this architecture, which offers interesting performance for instruction tuning
Beyond NLP, which is the focus of this blog post, encoder-decoder architecture is widely used in other fields such as audio or time series, for example. Note also that the encoder of such architecture is also used in some diffusion models.
That's why we've decided to focus on the T5
This article presents the optimisations we have implemented to efficiently pre-train a T5 in French with 147M parameters in a reasonable time (1,461 H for 419B tokens) and with limited resources (1 single A100; i.e. a computing budget of around 1,900 euros).
To achieve this, we designed CUDA/Triton kernels to make Flash Attention compatible with T5 and provide linear inference, thus extending the context size that can be taken into account by the model.
The pre-training code is available in our GitHub repository under Apache-2.0 license and weights on our Hugging Face account.
We therefore chose to work with a T5 and in practice with the nanoT5
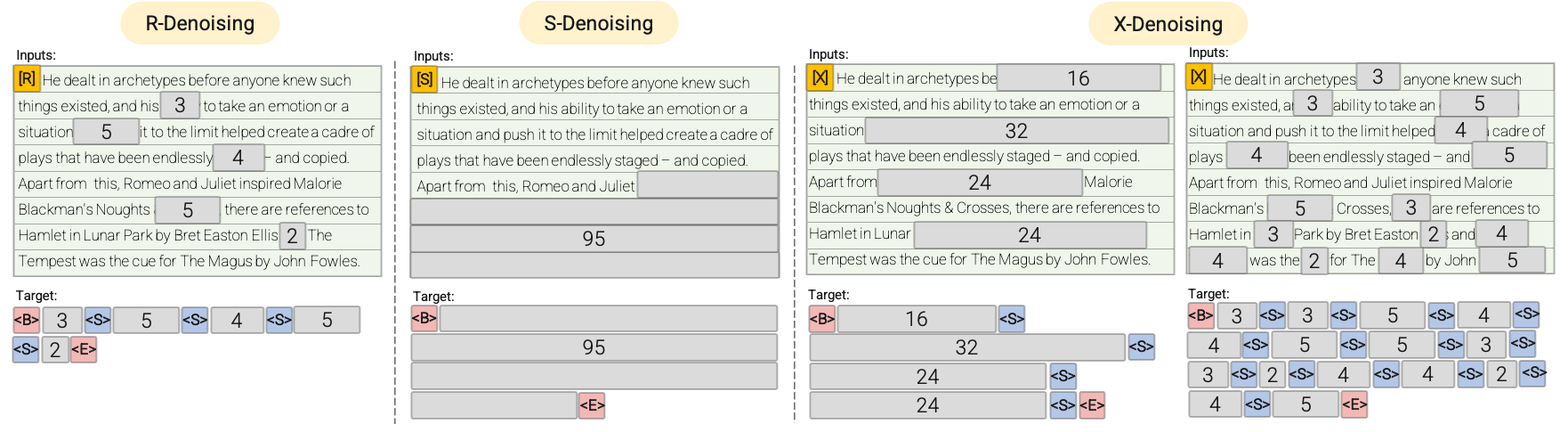
For pretext tasks during pre-training, we followed the UL2 ones
denoiser_list=[
{"mu": 3.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[R]"},
{"mu": 8.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[R]"},
{"mu": 4.0, "r": 0.0, "max_spans": 1, "prefix": "[S]"},
{"mu": 3.0, "r": 0.5, "max_spans": max_token_length, "prefix": "[X]"},
{"mu": 8.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[X]"},
{"mu": 64.0, "r": 0.15, "max_spans": max_token_length, "prefix": "[X]"},
{"mu": 64.0, "r": 0.5, "max_spans": max_token_length, "prefix": "[X]"}]
denoiser_proportions=[0.165, 0.165, 0.34, 0.0825, 0.0825, 0.0825, 0.0825]
with mu the n-gram size, r the masking percentage in the n-gram and prefix the type of pretext task.
The meaning of letters [R], [S] and [X] is described here
and we invite you to take a look at the following image in particular.
For a quick training, we decided to focus on the Flash Attention
Our work resulted in the pre-training of a T5 in French with 147M parameters: the FAT5 small.
The dataset we used is made up of the French part of the CulturaX corpus
This model was evaluated on five tasks: text summarization, binary classification, question answering, named entity recognition and sentence similarity.
With only two A100 (one 80GB and one 40GB), we had to spend some time implementing optimisations to get the best out of our hardware.
Indeed, before even training a model, or even modifying its architecture, we need to ensure that we are optimising the use of our GPUs' computing capacity.
There are several factors that can explain sub-optimal training of a deep learning model:
• Disk-bounded
• Memory-bounded
• Compute-bounded
Ideally, we would like the model to be limited by the speed of calculation, i.e. the GPU to be used at full capacity.
With this in mind, we worked on three main points:
• GPU disk optimisation
• GPU memory bandwidth optimisation
• Optimisation of the use of Tensor Cores
So it's a combination of hardware and software issues.
In the rest of this section, everything we have done/implemented to address the limitations encountered is available in a green box. Notes/comments can be found in a blue box.
Disk limitation occurs either during data loading or during pre-processing operations.
In both cases, the problem manifests itself as slowness.
If the limitation comes from disk access, there are several possible solutions:
Put data in RAM
This solves the problem radically, but assumes that the database fits into RAM, which is far from obvious given its small size.
So this is not the solution we have chosen.
Put data on a faster and/or less-used disk
If you have physical access to your GPU server, it is very useful to integrate NVMe in its configuration.
You also need to be careful not to have too many processes from different training pulling on the same disc. It is therefore preferable to have several small discs rather than one large one.
A beneficial indirect effect is that such a configuration costs less 😉
.parquet files are more efficient than .csv.
We can also use formats specifically developed for this purpose, such as the .beton from ffcv We use the Datasets library Arrow format.
Moreover, if the data loaded from the Hugging Face Hub has been added using the push_to_hub() function,
then the dataset is converted by default in parquet.
Readers are invited to consult the following
code which
illustrates how we proceed in our FAT5 tutorial applied to the Minipile dataset
If the limitation comes from the processing of data after they have been uploaded:
Several processes can be used to process data in parallel
For example, the parameter num_workers of the Dataloader of PyTorch
You can find in our code the values we use for this parameter for our FAT5 small.
The bottleneck can also come from the DataCollator
This is especially the case when there are complex tasks to perform (image masking or multiple denoisers on NLP tasks).
We can then build a custom DataCollator for the task.
On appliquera les méthodes traditionnelles pour optimiser la vitesse de celui-ci.
Similarly, using Numpy's vectorisation will allow lists to be processed more quickly than with for loops.
Generally speaking, Numpy is faster than PyTorch for this type of task.
You can also use compilation methods such as numba
We followed this principle and developed a custom DataCollator for our FAT5.
You can find the code here.
It manages UL2 pretext tasks and has a dynamic batch mechanism to reduce padding (more information in the next section)
As there was no implementation of UL2's DataCollator available in PyTorch until now,
we hope this may be useful for other work.
Effective padding
When working with sequences, there is a natural tendency to pad a set of sequences in order to build batches.
The padding tokens then generate unnecessary calculations.
The first thing to do is to limit padding to the maximum size sequence and not to a maximum value.
This is the dynamic padding technique.
With this approach, padding tokens may still remain. There are two ways of managing them:
• use a method for grouping data of similar sizes
(for example, this parameter
in the Transformers library
• concatenate different examples in a custom DataCollator.
We have opted for the second option and refer the reader back to the code our DataCollator.
More optimised heuristics probably need to be put in place.
We carried out a test by proposing a
function
in the DataCollator to sort input_ids and labels by descending length.
However, this is rather time-consuming for a minimal packaging gain.
More work needs to be done on this point.
Memory bandwidth limitation is more difficult to deal with. A memory-limited operation is one whose overall execution time is restricted by memory accesses. This is particularly the case for LLMs, especially at the inference level. The diagnosis can be made from the PyTorch profiler:

Another way of establishing a diagnosis is to use a simple nvidia-smi:
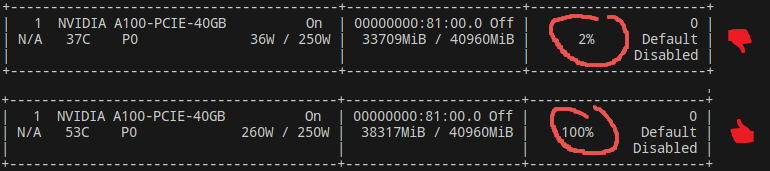
Useful for finding out if a problem is present, but gives limited information about the nature of the problem. That's why we prefer the profiler.
The main technique for optimising GPU memory bandwidth is to develop a CUDA kernel that merges several limiting operations into SRAM. This can limit the copying of large matrices into the HBM and then immediately reloading them into SRAM. This is now a common feature of decoder transformers thanks to the Flash Attention.
As Flash Attention does not manage the (additive) attentional biases of the T5, we extended it by developing a custom CUDA kernel. As mentioned in the introduction, we actually implemented two successive versions of this kernel. Without going into the details of the 650 lines of code in the implementation of the first version (which can be consulted here), the general and simplified idea (for a forward pass) is as follows:
While the first version of the kernel is generic, the second (available here) is specific to the working of models with relative positional encoding (which is the case of the T5). The general and simplified idea (for a forward pass) is as follows:
In this way, whereas the first version of the B bias matrix required a quadratic memory,
here we are back to a linear memory enabling inferences to be performed on tens of thousands of tokens.
To design this second version, we were inspired by the TurboT5's Triton kernel, which we ported to CUDA and extended to full BF16.
Note that the two versions developed can be used with several positional encodings.
We invite the reader to consult this file
containing classes compatible with Flash Attention for the
RelativePositionalEncoding
At the time of writing, the two pull requests (one for each kernel version,
available here
and here)
opened on the official Flash Attention repository have not been merged.
Readers will therefore have to temporarily recompile our custom Flash Attention patches to be able to use our models.
Readers are invited to consult the Benchmark section further below to see the improvements brought by these two kernels.
Although we didn't use them, it should be noted that some libraries contain merged implementations of common operators, for example Apex
Triton
A Triton implementation of the
Flash Attention 2 managing attention bias
is provided for those who do not wish to recompile a custom patch for Flash Attention.
To do this, we based ourselves on the FlagAttention repository
In addition to this implementation (whose use is optional), other parts of the architecture have been optimised using ad hoc Triton kernels, namely:
• the cross entropy loss (and the loss z
• the RMSNorm layer
We drew inspiration from Unsloth
Readers are invited to refer to the Benchmark section below to see the impact of this optimisation.
torch.compileA simpler approach is to compile the models with torch.compile.
PyTorch then takes care of making the possible merges, possibly by reordering operations.
This involves hunting down breaks in the compilation graph, which are returns to an eager execution mode that have a negative impact on the performance of the operation.
See the official documentation for more details.
Another possibility is to use both a custom kernel and torch.compile.
The implementation of this option has been greatly simplified since the
version 2.4 of PyTorch.
Readers are invited to refer to the benchmark section at the end of the article to measure the memory performance performance of the various techniques described.
Recent GPUs have units dedicated to tensorial operations: the TensorCore. Using them correctly is essential.
Once again, to establish a diagnosis, it is advisable to refer to the PyTorch profiler, which indicates the proportion of TensorCore used for each CUDA kernel:

The optimisations that can be made are:
The first is to use tensor sizes that are multiples of 8 or 64. Please refer to the Nvidia documentation, in particular this article and this article to determine the multiple to select according to the desired precision.
With this in mind, we trained a tokenizer of size 32 768 (8**5),
following this observation by KARPATHY.
This is a BPE tokenizer
Readers can find the code used here.
Changing optimisers from the initial implementation of the model can be a good way of speeding up convergence of the model (although it may prevent the results of the original paper from being reproduced).
Optimisers speed up convergence by allowing large batch sizes, as in the case of LAMB
More efficient versions of the optimisers can also be used, such as the fused option
in the Adam optimiser available in PyTorch
or the optimisers available in Apex.
We used the original T5 optimiser, AdamWScale.
For hyperparameter values, we use lr = 5e-3, betas = (0.9, 0.999), eps = 1e-6 et weight_decay = 0.0
based on the observations of Wilson WONGSO.
Indeed, it turns out that not all the alternative optimisers tested converged.
We have added the parameter foreach in our version of AdamWScale.
bf16Recent GPUs make it possible to full exploit the use of reduced precision
(enabling a gain of a factor of 2 in throughput compared to the fp32 precision).
The bf16 is only available on Ampere or more recent architectures, but allows you to avoid loss scaling
fp16
thanks to a wider dynamic range (the exponent is coded on 8 bits like the fp32).
With this in mind, we train our models in bf16.
More specifically, while at the beginning of our experiments we used bf16-mixed, we have used the
Kahan summation algorithm
so that we can use full bf16 in our optimizer.
Once again, the code for our optimizer is accessible here.
Certain techniques exist to limit the use of GPU memory by the model, such as the
gradient checkpointing
or ZeRO-type methods
Using several GPUs is tricky. Done naively, it can result in lower performance than implementation on a single GPU, wasting computing resources. This is particularly the case when bottlenecks occur in communications between GPUs. The aim is to ensure that the model is not limited by the bandwidth between the cards, or to ensure that the cards are connected with sufficient bandwidths via techniques such as NVLink for example.
It should also be noted that optimisation techniques generally require all the GPUs to be synchronised at the end of a batch. As a result, if one GPU is slower than the others (or is being used by another process), the model is limited to the speed of the slowest GPU in the group.
Having pre-trained our model on a single 80GB A100, we were unable to experiment with parallelism.
We looked at the elements listed above with a view to optimising the pre-training of our model.
In practice, we then need to fine-tune it to specialise on the final tasks that interest us.
To do this, we use heads. For the vanilla T5,
five are available in Transformers to perform all feasible tasks:
T5ForConditionalGeneration,
T5ForSequenceClassification,
T5ForTokenClassification,
T5ForQuestionAnswering
et T5EncoderModel.
Here again, optimisation work can be carried out.
For conditional generation, the main point is to ensure that the generation process is efficient.
For heads involved in classification tasks (sequence, NER and QA), it is necessary to ensure that the encoder part
of the T5 is used, since the decoder is not essential for these tasks, as shown in EncT5
The last head is simply used to retain only the encoder part of an encoder-decoder model. It therefore does not need to be optimised.
About the headForConditionalGeneration, our
implementation
is based on the generation process available in the
nanoT5
because it is 14% faster than the Hugging Face implementation.
For classification heads, the implementation is available in this
file.
This file is separate from the modelling file because our implementations differ from those available in Transformers.
Indeed, heads T5ForSequenceClassification and T5ForQuestionAnswering available in Transformers are based
on the T5 encoder and decoder, which is inefficient.
We therefore recoded these two heads to use only the encoder.
We then followed the same structure as the T5ForTokenClassification head available in Transformers,
which also only uses the encoder, and so have used as is.
The number of TFLOPS (trillions of floating-point calculations a processor can perform in one second) is probably the most telling metric to demonstrate the impact of the optimizations carried out.
We compare four approaches:
• SPDA (Scaled Dot Product Attention) implementation with full bias,
• the same implementation but in Triton,
• the Flash implementation Attention RPE, i.e. the second kernel we've developed (can be seen as turboT5 but in C++/Cuda),
• the Flash implementation Attention i.e. without bias. We've included it for reference but it's unusable in practice for a T5.
For the forward pass, we have:

For the forward pass, the Triton approach achieves 1.34 times more FLOPS than the SPDA approach, while the Flash Attention RPE approach achieves 1.99 times more FLOPS than the SPDA approach.
We can also see that our bf16 implementation is equivalent to fp16 (doing even better at size 512).
Following this benchmark, we decided to train our French model in bf16, head_dim = 128 and with a sequence of 1024.
For the backward pass, we have:

For the backward pass, the Triton implementation performed worse than SPDA, with 0.71 times the FLOPS of SPDA. The Flash Attention RPE implementation is more or less equivalent to SPDA (1.018 times more FLOPS).
We can also observe that Triton in head_dim 64 is more efficient than Triton in head_dim 128.
We mentioned previously that we had optimised parts of the architecture using ad hoc Triton kernels, namely the cross-entropy and RMSNorm layer.
The following benchmarks should illustrate why.
For cross-entropy, we get a forward pass 7 to 11.4 times faster, a backward pass 3.26 to 3.75 times faster as well as a memory reduced by a factor of 4:

For the RMSNorm layer, we get a forward pass 3 to 5 times faster, a backward pass 2.33 to 4.33 times faster as well as a memory reduced by a factor of 3.2:
.

Note that all the benchmark graphs can be generated automatically using the following code.
We applied our work to French by pre-training a 147M parameter model.
The dataset we used is a mixture of CulturaX, Wikipedia, justice_fr and The Stack.
Our tokenizer of size 32,768 (8**5) is trained on CulturaX and The Stack.
Our model is pre-trained on a sequence of 1,024 tokens.
We wanted to compare the performance of our model with other previously published French-language models, such as CamemBERT
For this reason, we thought it important to make comparisons with an equivalent number of tokens seen.
We therefore tried to estimate the number of tokens seen by these two models using the formula number of steps × sequence size × batch size. We couldn't find the information in the BARThez publication to do this. For CamemBERT, we estimate a maximum of 419.4B tokens. This figure could actually be lower, as we don't know the number of padding tokens seen by this model (where in our case, we don't use any). So we have pre-trained our model on the maximum number of tokens seen by the CamemBERT.
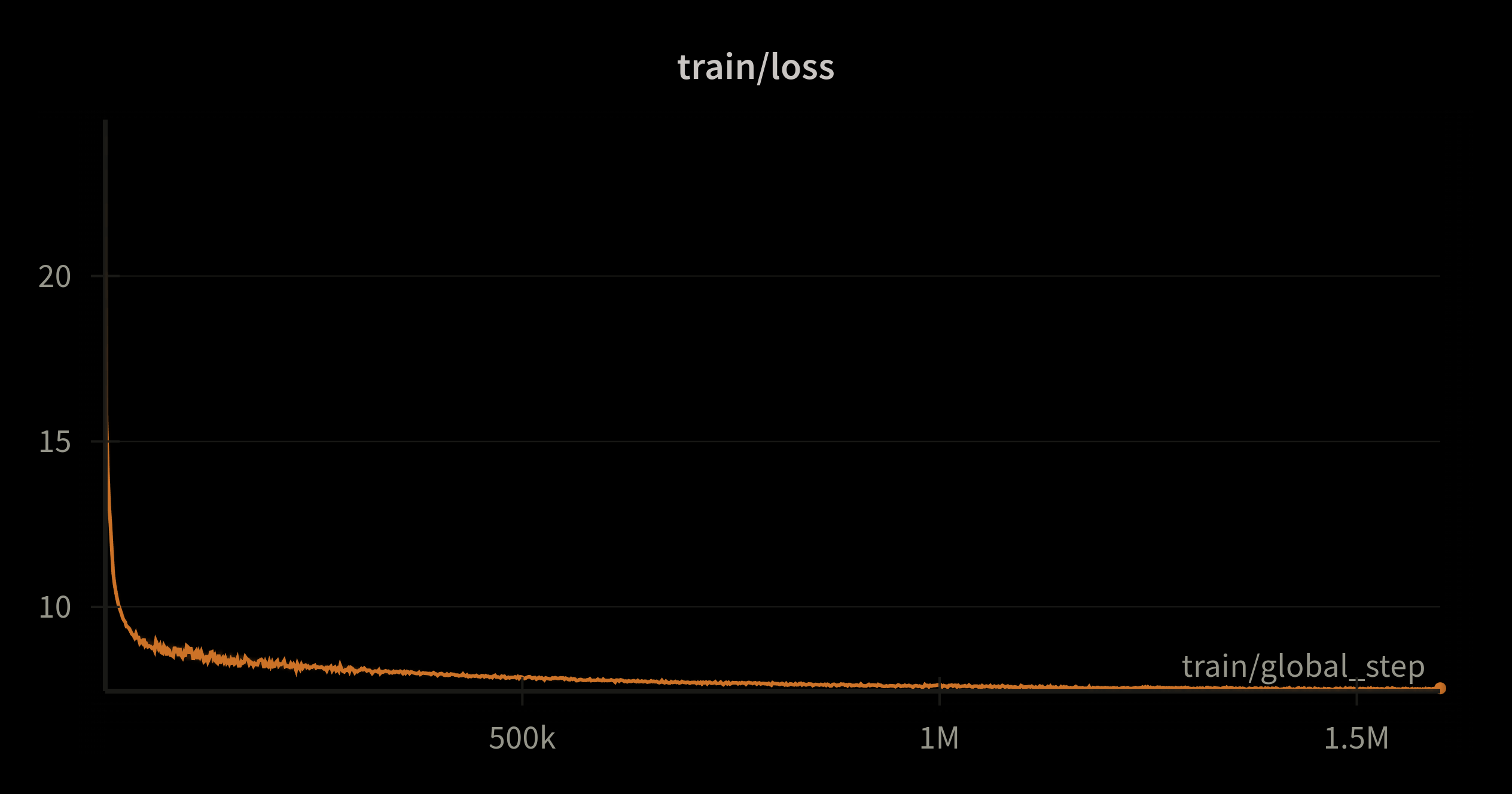
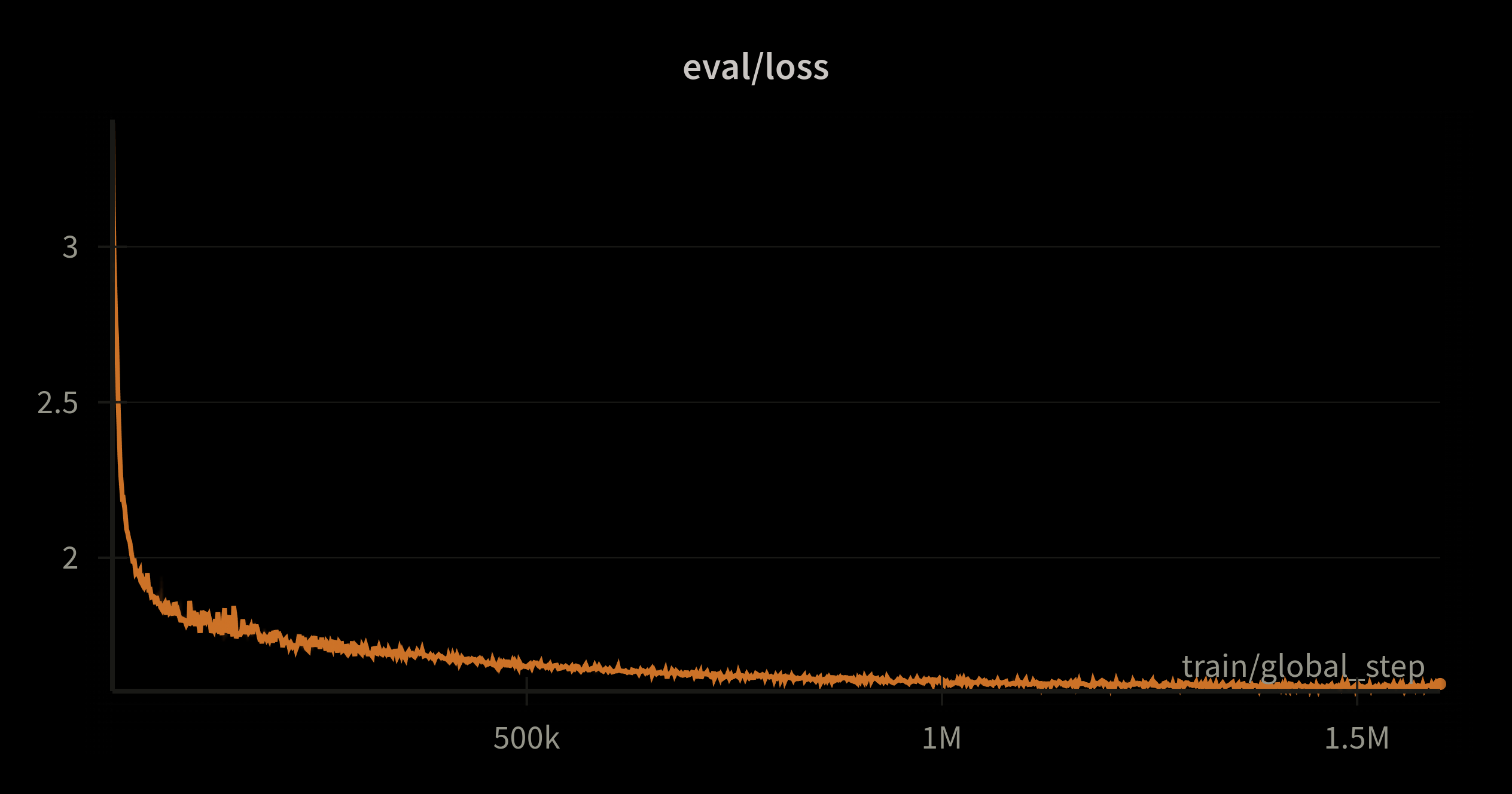
We were also interested in comparing our model against itself, i.e. we evaluated its performance on downstream tasks every 100,000 steps (~26 billion tokens) during pre-training.
In the table below, we have listed the number of tokens equivalent to each interval of 100,000 steps.
| Model | Number of tokens ✝ |
|---|---|
| FAT5-small-100K | 26,214,400,000 (100,000 × 1,024 × 256) |
| FAT5-small-200K | 52,428,800,000 (200,000 × 1,024 × 256) |
| FAT5-small-300K | 78,643,200,000 (300,000 × 1,024 × 256) |
| FAT5-small-400K | 104,857,600,000 (400,000 × 1,024 × 256) |
| FAT5-small-500K | 131,072,000,000 (500,000 × 1,024 × 256) |
| FAT5-small-600K | 157,286,400,000 (600,000 × 1,024 × 256) |
| FAT5-small-700K | 183,500,800,000 (700,000 × 1,024 × 256) |
| FAT5-small-800K | 209,715,200,000 (800,000 × 1,024 × 256) |
| FAT5-small-900K | 235,929,600,000 (900,000 × 1,024 × 256) |
| FAT5-small-1000K | 262,144,000,000 (1,000,000 × 1,024 × 256) |
| FAT5-small-1100K | 288,358,400,000 (1,100,000× 1,024 × 256) |
| FAT5-small-1200K | 314,572,800,000 (1,200,000 × 1,024 × 256) |
| FAT5-small-1300K | 340,787,200,000 (1,300,000 × 1,024 × 256) |
| FAT5-small-1400K | 367,001,600,000 (1,400,000 × 1,024 × 256) |
| FAT5-small-1500K | 393,216,000,000 (1,500,000 × 1,024 × 256) |
| FAT5-small-1600K | 419,430,400,000 (1,600,000 × 1,024 × 256) |
| camembert (base or large) | 419,430,400,000 (100,000 × 512 × 8,192) |
✝ equivalent to number of steps × sequence size × batch size
We focused on five tasks:
• Summarising texts to illustrate the use of the head T5ForConditionalGeneration,
• Binary classification to illustrate the use of the head T5ForSequenceClassification,
• Named entity recognition to illustrate the use of the head T5ForTokenClassification,
• Question answering to illustrate the use of the head T5ForQuestionAnswering.
• Sentence similarity to illustrate the use of the head T5EncoderModel.
Classification tasks seem to us important to evaluate, as they are generally ignored by benchmarks of generative language models, even though they are often used in practice by companies (document retrieval, classification for customer reviews, data anonymization, etc.).
The fact that 6 and a half years after its release, BERT
In the following tables, we underline for FAT5 the line with the best result for each task. We interpret the results of the generation part after the text summarization table. The classification results are interpreted after the binary classification, QA, NER and sentence-similarity tables.
For this task, we used the dataset orange_sum
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| FAT5-small-100K (147M) | 28.17 | 10.60 | 20.62 |
| FAT5-small-200K (147M) | 28.72 | 10.86 | 20.68 |
| FAT5-small-300K (147M) | 28.76 | 10.85 | 20.63 |
| FAT5-small-400K (147M) | 28.59 | 10.76 | 20.60 |
| FAT5-small-500K (147M) | 28.98 | 10.97 | 20.72 |
| FAT5-small-600K (147M) | 29.04 | 11.20 | 20.89 |
| FAT5-small-700K (147M) | 28.72 | 10.87 | 20.77 |
| FAT5-small-800K (147M) | 29.00 | 10.91 | 20.78 |
| FAT5-small-900K (147M) | 29.30 | 11.34 | 21.22 |
| FAT5-small-1000K (147M) | 29.10 | 11.21 | 21.08 |
| FAT5-small-1100K (147M) | 29.43 | 11.40 | 21.15 |
| FAT5-small-1200K (147M) | 29.30 | 11.38 | 21.18 |
| FAT5-small-1300K (147M) | 29.38 | 11.38 | 21.18 |
| FAT5-small-1400K (147M) | 29.29 | 11.18 | 21.14 |
| FAT5-small-1500K (147M) | 29.48 | 11.48 | 21.22 |
| FAT5-small-1600K (147M) | 29.30 | 11.27 | 21.10 |
| Barthez |
31.44 | 12.77 | 22.23 |
| mBarthez (458M) | 32.67 | 13.73 | 23.18 |
We can see that our model performs worse than the Barthez. We can put forward a few hypotheses on this subject.
Firstly, it's likely that our text generation process is not optimal. Not knowing the one used by the Barthez, we simply used the default parameters of the generate function in transformers to avoid giving our model an advantage with a more sophisticated generation process.
Secondly, we didn't use a prompt to condition the generation, which could have benefited our model since the T5 is the model that introduced this system.
Thirdly, the Barthez surely saw more tokens than our model. Although we can't determine this number from the authors' publication, it is indicated that this is a BART model
We use a cleaned version of the allocine dataset
| Model | Accuracy |
|---|---|
| FAT5-small-100K (67.4M) | 96.05 |
| FAT5-small-200K (67.4M) | 96.20 |
| FAT5-small-300K (67.4M) | 96.48 |
| FAT5-small-400K (67.4M) | 96.60 |
| FAT5-small-500K (67.4M) | 96.60 |
| FAT5-small-600K (67.4M) | 96.60 |
| FAT5-small-700K (67.4M) | 96.68 |
| FAT5-small-800K (67.4M) | 96.59 |
| FAT5-small-900K (67.4M) | 96.75 |
| FAT5-small-1000K (67.4M) | 96.62 |
| FAT5-small-1100K (67.4M) | 96.69 |
| FAT5-small-1200K (67.4M) | 96.71 |
| FAT5-small-1300K (67.4M) | 96.69 |
| FAT5-small-1400K (67.4M) | 96.65 |
| FAT5-small-1500K (67.4M) | 96.57 |
| FAT5-small-1600K (67.4M) | 96.69 |
| distillcamembert (68.1M) | 96.74 |
| camembert-base (111M) | 97.27 |
| camembert-large (337M) | 97.15 |
Note: in this and the following tables, distillcamembert refers to a distilcamembert-base
For this task, we used frenchNER in its 4 entities (PER, LOC, ORG, MISC)
| Model | F1 PER | F1 LOC | F1 ORG | F1 MISC |
|---|---|---|---|---|
| FAT5-small-100K (67.1M) | 96.51 | 94.48 | 87.24 | 75.81 |
| FAT5-small-200K (67.1M) | 96.90 | 94.83 | 88.78 | 76.82 |
| FAT5-small-300K (67.1M) | 97.25 | 95.11 | 88.86 | 77.48 |
| FAT5-small-400K (67.1M) | 97.18 | 95.08 | 89.11 | 77.42 |
| FAT5-small-500K (67.1M) | 97.25 | 95.16 | 89.16 | 76.91 |
| FAT5-small-600K (67.1M) | 97.19 | 95.19 | 88.85 | 76.88 |
| FAT5-small-700K (67.1M) | 97.17 | 95.14 | 89.39 | 76.82 |
| FAT5-small-800K (67.1M) | 97.34 | 95.20 | 89.18 | 77.27 |
| FAT5-small-900K (67.1M) | 97.19 | 95.21 | 89.04 | 76.83 |
| FAT5-small-1000K (67.1M) | 97.31 | 95.26 | 89.24 | 76.84 |
| FAT5-small-1100K (67.1M) | 97.11 | 94.99 | 88.52 | 76.30 |
| FAT5-small-1200K (67.1M) | 97.19 | 95.11 | 88.79 | 76.86 |
| FAT5-small-1300K (67.1M) | 97.15 | 95.00 | 88.62 | 76.58 |
| FAT5-small-1400K (67.1M) | 97.22 | 95.09 | 89.01 | 77.00 |
| FAT5-small-1500K (67.1M) | 97.32 | 95.34 | 89.39 | 77.30 |
| FAT5-small-1600K (67.1M) | 97.14 | 95.22 | 89.24 | 76.88 |
| distillcamembert (67.5M) | 97.26 | 95.24 | 89.10 | 79.88 |
| camembert-base (110M) | 97.80 | 95.78 | 90.27 | 81.38 |
| camembert-large (336M) | 98.17 | 96.37 | 91.87 | 83.35 |
We wanted to finetune our model on this task but realized that our tokenizer has two problems.
Firstly, we forgot to add the token at the beginning of the sentence.
Secondly, we decided to use a fast BPE tokenizer. We learned afterwards that the `add_special_tokens=True` argument doesn't work with this type of tokenizer.
Correcting these two points requires us to post-process the tokenizer's encodings before performing our finetuning task, which isn't elegant and requires time we don't have right now.
We invite the reader to take the results of this section with a grain of salt.
We performed a finetuning on this task in order to verify that the T5EncoderModel head was working, but we are not focusing on the results obtained because we are questioning the quality of the benchmark on which we are evaluating the models, namely MTEB FR
Indeed, Nils Reimers, creator of the MTEB, recently questioned in a tweet the relevance of this benchmark, declaring it "dead".
Earlier in the year, we observed data leaks and duplications in this benchmark
(see here and
here).
Alexey Vatolin then extended these observations to include empty lines (see here).
In the table below, we finetuned on a cleaned version of the dataset stsb_multi_mt
| Model | Average | Classification | Clustering | PairClassification | Reranking | Retrieval | STS | Summary |
|---|---|---|---|---|---|---|---|---|
| FAT5-small-400K (67.1M) | 52.2 | 59.8 | 39.1 | 77.5 | 56.1 | 29.1 | 74 | 29.8 |
| distillcamembert (68.1M) | 51.3 | 60.7 | 37.4 | 77 | 51.1 | 25.2 | 76.4 | 31.3 |
We can see from the masked accuracy convergence graph that the performance of the encoder part of the model progresses initially before flattening out.
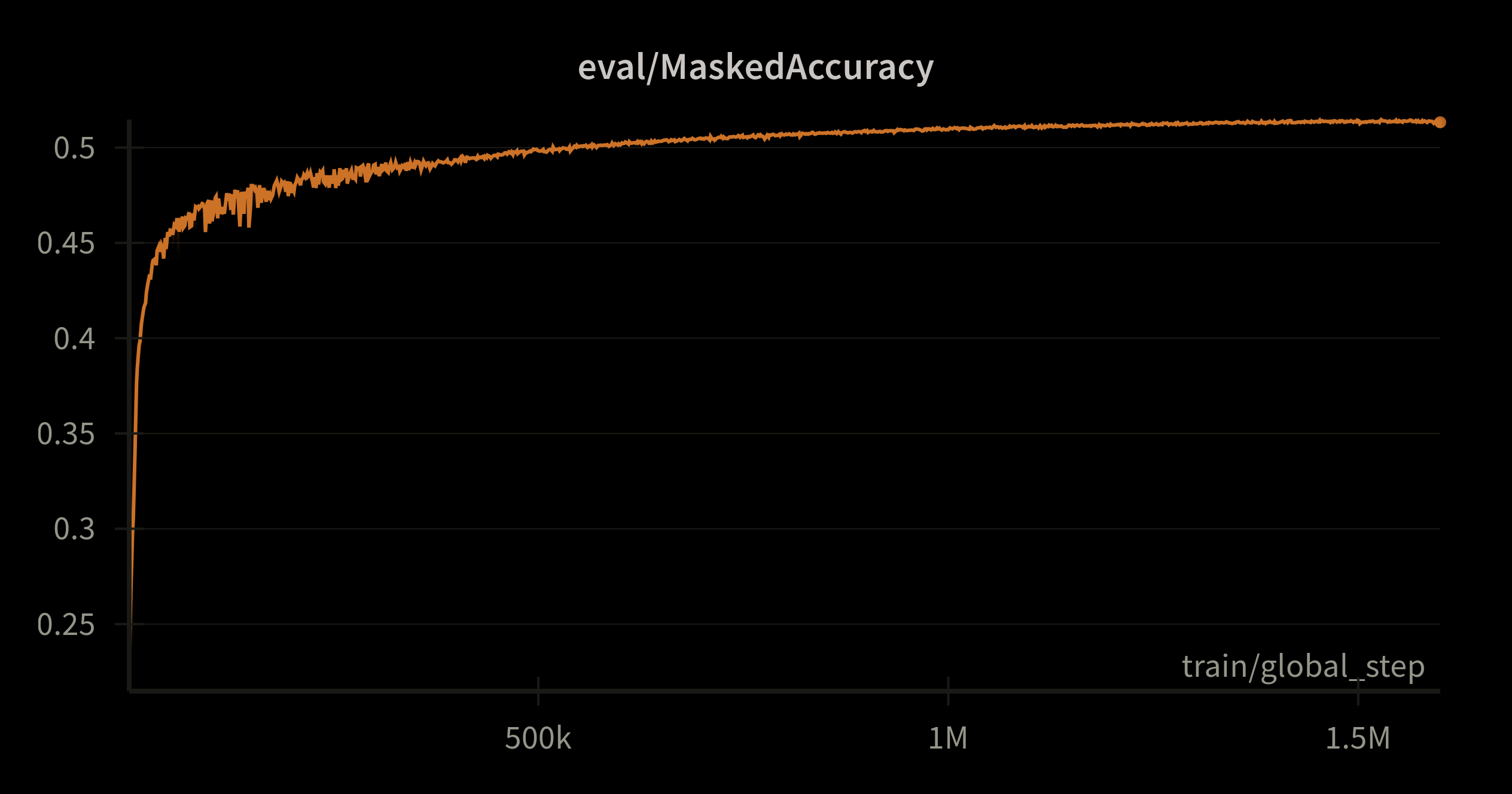
This phenomenon can also be observed in the finetuning results: FAT5 matches the performance of distilcamembert at around 800 or 900K steps (except for the MISC entity for the NER task), but does no better beyond that. This is nevertheless encouraging in view of scaling up, since distilled models derived from larger models usually perform better than trained models from scratch.
Note that this sort of plateau in performance needs to be confirmed by carrying out several executions with different configurations (notably at seed level), in order to propose results in the form of an interval instead of a single result (for each step evaluated, we use a seed of 42).
It should also be mentioned that this capping for the encoder part has already been observed by other authors. One example is CamemBERT(a) 2.0
A final observation that can be made is that if performance plateaus, it is possible to afford to stop pre-training earlier and thus reduce costs.
In the table below, we list cost estimates (in euros) for the pre-training of our model according to various cloud providers.
For each of them, we base ourselves on the hourly price of an A 100 80GB offered on December 20, 2024.
We show two cases: pre-training on 262 billion tokens (the threshold at which performance on classification tasks begins to plateau and marginal gains become low) on 419 billion tokens (the maximum number of tokens seen by CamemBERT).
| Cloud provider | Hourly rate for an A 100 (in €) | Price for 262B tokens (in €) | Price for 419B tokens (in €) | Note |
|---|---|---|---|---|
| Sesterce | 1.29 | 1,182 | 1,891 | |
| AWS | 1.77 | 1,616 | 2,586 | |
| OVH | 2.75 | 2,475 | 3,960 | By opting for monthly rather than hourly payment, the price in both cases is €2,200. |
| Azure | 3.31 | 3,021 | 4,833 | The hourly price was calculated from the monthly price of 8 A100. |
| Google Cloud | 3.52 | 3,214 | 5,143 |
Carbon emissions were estimated using the Machine Learning Impact calculator
Our model was pre-trained on a single A100 PCIe 80GB, on a private infrastructure.
For carbon efficiency, we based ourselves on the daily numbers given by electricitymaps for France during our pre-training period.
The finetunings were carried out on a single A100 PCIe 40GB.
As execution time is generally counted in hours or even minutes, for carbon efficiency we refer to the electricitymaps numbers for the hour in question rather than the daily number.
We estimate the emissions of our model at 14.084 kg eq. CO2, including 13.5 kg eq. CO2 for pre-training and 0.584 kg eq. CO2 for the 49 finetunings.
To this, we must add additional emissions estimated at 6.24 kg eq. CO2.
They correspond to the finetuning of models to establish baselines against which to compare (0.475 kg eq. CO2), to our preliminary work in bfp16 mixed (4.735 kg eq. CO2 for the pre-training of three different models over 300K steps) and to tests in bfp16 full prior to the training of our final model (1.03 kg eq. in pre-training of a model half the size over 400K steps).
In total, we estimate the carbon footprint of our work at 20.324 kg eq. CO2.
For the pre-training phase (we don't have enough information to make estimates for the other phases), it is then possible to compare us with the other French pre-trained models listed above:
| Model | Time (H) | Emissions (kg Co2 eq) | Note |
|---|---|---|---|
| Camembert | 6,144 | 106.91 ✝ | 24H × 256 Tesla V100-SXM2-32GB at 58g (average over 2019) The authors do not specify the numbers for the large version. |
| Flaubert base |
13,120 | 190.24 to 228.29 ✝ | 410H × 32 V100 at 58g (average over 2019) The V100 type is not specified (V100-SXM2-32GB ? V100-SXM2-16GB ? V100-PCIE-16GB ?) |
| Flaubert large |
49,920 | 723.84 to 868.61 ✝ | 390H × 128 V100 at 58g (average over 2019) The V100 type is not specified (V100-SXM2-32GB ? V100-SXM2-16GB ? V100-PCIE-16GB ?) |
| Barthez | 7,680 ★ | 107.52 to 129.02 ✝ | 60H × 128 V100 at 56g (average over 2020) The V100 type is not specified (V100-SXM2-32GB ? V100-SXM2-16GB ? V100-PCIE-16GB ?) |
| FAT5-small | 1,461 | 13.5 | 1 461H × 1 A100 to 36.96 g (average between 2024-18-10 and 2024-19-12) |
✝ the numbers given are estimates based on the information provided by the authors in their publication
★ we indicate only the hours for the French pre-training applied on top of the initial English pre-training on which the model is based
Our contribution focuses on French, with the introduction of a new model. For other languages, we can't afford to carry out work on the same magnitude.
Nevertheless, we provide a code for adapting already pre-trained (m)T5/FLAN-T5 weights
Please note, however, that this adaptation is limited, since the additional pre-training will have to be carried out in the precision of the original model. For example, if the model's weights are in fp32 (which is the case with the FLAN-T5), training will not be as fast as with the FAT5, which is in bf16.
For English speakers, we have already adapted the weights of the various FLAN-T5 versions to our method. All weights can be found in this Hugging Face collection.
If you'd like to pre-train your own model (to specialize in a specific domain, for example, and thus benefit from a customized tokenizer), we refer you once again to the tutorial showing how to pre-train a model on minipile. Note that we have tested and trained the model in the tutorial on an A100, which may or may not work with other GPUs.
Let's end this article by mentioning what we intend to do, or at least would like to do, as a follow-up to this work.
These are things that should already have been in this article, but took more time than expected.
Typically, we've finished building datasets but haven't had time to do the finetunings.
The aim is to complete these tasks in the near future, so that we can include the results in an update to this blog post.
The current FAT5 is usable. However, due to problems with the tokenizer resulting in inelegant post-processing for certain tasks, we're not excluding the possibility of re-training a model (on 1M steps only) with a new tokenizer allowing simpler use of the model.
We'd like to test FAT5's text generation capabilities in a more optimal way, in particular through the use of prompts, by developing an instruct model.
For this, we have DFP (Dataset of French Prompts)
Beyond NLP tasks, we also have over 2M open QA prompt rows, which should enable us to test FAT5 on more general tasks/knowledge.
The development of this instruct model should also enable us to work on its alignment, in particular via a dataset of 12M rows to perform DPO in French.
Pre-training is performed on sequences of 1,024 tokens. However, the CUDA kernel we've developed supports positional encodings that greatly extend the context size, as well a linear inference.
With this in mind, we've created two datasets of long sequences in French (one of QA, one of text summaries) on which we'd like to finetune our model.
The items listed below are longer-term ideas. In other words, they will take time to implement and will be the subject of a new blog post if necessary.
Although we're already satisfied with the memory optimisations achieved via our CUDA kernel, we think we can take these results further using other techniques. For example, we can cite the CCE (Cut Cross-Entropy) method
In addition, while we have concentrated on pre-training, more work needs to be done on inference, which in practice consumes the most resources over time once the model is in production. We are thinking in particular of using the SageAttention2
In this work, we present a linear memory model.
A further improvement would be that, in addition to this memory, the model operates with linear computations.
The idea is to replace traditional quadratic attention with another form of attention.
We can think of some already applied to the T5, such as that of LongT5
LoLCATs
T5/FLAN-T5 have been trained to 11 billion parameters, demonstrating that this architecture can scale.
We would like to offer larger models with a FAT5-base and a FAT5-large with 305M and 973M parameters respectively, which we would then like to distil. The aim is to offer models that consume as little as possible in routine/inference.
We also expect the distilled models to perform better than models of equivalent size trained from scratch.
This should also allow us to propose models that will be used in practice. Indeed, in the current state for French, if the user is more motivated by performance than by the memory size of the model, he has more interest in using a CamemBERTa 2.0 for classification tasks. The present FAT5 should therefore be seen more as a proof of concept before being scaled up to make it competitive.
In this work, we used "generic" French data, mainly from CulturaX. During the training of our model, Hugging Face introduced the FineWeb2 dataset
Beyond generic French, we particularly want to be able to apply our methodology to specific domains (medicine, regional variants of French, etc.).
To do this, we would need to train a new dedicated tokenizer and perform a new pre-training for each of the chosen domains.
The advantage of the optimisations implemented and presented in this blog article is that they enable a significant reduction in the cost of pre-training.
We would then like to conduct a comparison between these small specialised models vs. large generic models.
The final direction we would like to explore is an update of the T5 architecture. As encoder-decoders have been neglected, they have not benefited from the improvements that decoder models have received in recent months (more recent activation or normalisation layers, multi-token prediction
We introduced the FAT5 (Flash Attention T5) model, detailing our approach to optimizing various elements of the pre-training and finetuning processes.
This is based on kernels that enable Flash Attention to be used with a T5 and give the model a linear memory.
In particular, we've applied our work to French as a proof of concept, and made sure that it can also be used in any other language.
We hope that our method, which enables a model with 147M parameters to be pre-trained from scratch at a limited cost, will be useful for people with limited computational resources.
It also opens the way for a possible comeback of encoder-decoder models, rather than only decoder models.
@misc {FAT5,
title = { FAT5: Flash Attention T5 },
author = { Boris ALBAR and Loïck BOURDOIS },
organization = { Centre Aquitain des Technologies de l'Information et Electroniques },
year = 2025,
url = { https://huggingface.co/spaces/CATIE-AQ/FAT5-report },
doi = { 10.57967/hf/4160 },
publisher = { Hugging Face }
}
{kind=link}